Languages pour la metadonnée - une vue d'ensemble
© Jean-Marc Vanel 2002-2004 - première
version
Dernière
mise à jour (Last update):
- Sommaire
Introduction
Le mot "metadonnée" a deux sens passablement différents:
- la description formelle de données complexes en termes de
structure et de types simples (nombres, dates), e.g. SQL, XML Schema
UML,
OWL, etc
- un ensemble de propriétés génériques
attachées à des documents divers, telles que auteur,
date, catégorie, copyright, etc, e.g. Dublin Core
Le point commun aux deux sens est "la donnée sur la
donnée". On s'intéresse ici au sens 1.
En fonction du style de données, de l'application
envisagée, et des implémentations on choisira SQL, UML,
Java Bean, etc comme
source première de metadonnée. En suite à partir
de cette
source première on pourra à l'aide de differents outils
générer
un autre format de metadonnée et de donnée. On pourra
ainsi
intégrer des outils, des implémentations, être
ouvert
et évolutif.
Ce choix est la clé de voute d'un système. En effet
à partir de là le stockage s'en suit automatiquement; on
peut également, ce qu'on ne fait pas assez,
générer des IHM (application cliente, pages Web). De plus
les règles de validation sont souvent (plus on moins) contenues
dans la metadonnée. Pour achever un système
opérationnel, il ne reste qu'à implémenter des
opérations métier, et choisir des implémentation
génériques: serveurs, bases de données, IHM.
Encore faut-il choisir à bon escient son format de
metadonnée. Cet article veut donner une vue d'ensemble.
On s'attend à trouver de plus en plus de metadonnée
réutilisable sur Internet. Un exemple est le réservoir de
Schémas XML  de xml.org qui contient des dizaines de
vocabulaires
XML classés par métiers. On peut aussi trouver dans des
logiciels
libres des schemas de bases de données, ou en extraire des
classes
métier. Cependant il faut dire que partager des conceptions
réutilisables
n'est pas (encore) un mode de travail répandu dans le monde du
libre.
de xml.org qui contient des dizaines de
vocabulaires
XML classés par métiers. On peut aussi trouver dans des
logiciels
libres des schemas de bases de données, ou en extraire des
classes
métier. Cependant il faut dire que partager des conceptions
réutilisables
n'est pas (encore) un mode de travail répandu dans le monde du
libre.
Les formats de
metadonnée
Il faudrait caractériser les différentes façons
de spécifier la metadonnée:
- SQL Data Definition Language
- XML Schema
- XML DTD
- Relax NG
- Schematron
- XMI (UML), diagrammes de classe seulement
- Java Beans
- RDF Schema
- DAM+OIL
- Topic Maps
On peut introduire une relation d'ordre définie ainsi:
S1 < S2
veut dire que S2 est une spécification strictement plus
détaillée que S1. Précisément tout ce qu'on
peut exprimer en language S1 peut être traduit en S2 sans perte
d'information. Par contre il
existe des constructions en S2 qu'on ne peut traduire en S1.
Metadonnée XML
On a d'ores et déjà des inégalités :
DTD < XML Schema
SQL Data Definition Language < XML Schema
La première est évidente : c'est un des buts de
conception de XML Schema.
La deuxième est moins évidente mais en passant en revue
les possiblités de SQL on voit que tout y est dans XML Schema:
- types de données
- clés primaires et étrangères
- élément non nul
La traduction des données peut au choix faire appel à une
convention de correspondance ou être "verbatim". Pour faciliter
l'extraction en XML d'une ligne de SGBDR, on peut mettre dans un
même élément XML toutes les lignes appelées
par des clés étrangères. Mais on peut aussi
être "verbatim" et traduire chaque table par un
élément XML, puis chaque ligne par un
élément ou par un attribut XML.
Un exemple d'une convention de correspondance est l'association 1-n
entre une commande commerciale et les articles commandés. Alors
la table de jointure "articles commandés" n'apparait en tant que
telle dans le XML, mais à travers des
sous-éléments des
éléments <commande>. Cette convention est
ici classique et parait naturelle, mais ce n'est sûrement pas la
seule possible.
D'autre part l'inégalité est stricte car des contraintes
sur la cardinalité ou sous forme d'expressions
régulières en XML Schema ne peuvent pas être
écrites en SQL standard. Cependant ces contraintes peuvent
être garanties par des triggers. Ceci est
classique dans les SGBDR, mais non standardisé. Par contre dans
les
bases de données natives XML, imposer à tout instant la
conformité à un XML Schema est encore une
fonctionalité d'avant-garde. Il vaut mieux dans ce contexte des
bases de données natives XML recourir à des contraintes
exprimées en XSLT, ou encore plus simplement en XPath.
Maintenant entre les langages de Schema pour XML, je pense qu'on a
(presque)
XML Schema < Schematron
Les relations structurelles:
présence,
type, nombre et choix des sous-éléments sont exprimables
avec
XPath. Il est clair que Schematron a des fonctionalités plus
avancées
que XML Schema, puisqu'il est basé sur XPath, qui permet de
comparer
des éléments entre eux (exemple: spécifier un
rapport
d'aspect pour un rectangle). Cependant XML Schema a certaines
fonctionalités
non reproductible en Schematron:
- expressions régulières
- typage fin du contenu textuel, par exemple date (pour les nombres
ou peut se débrouiller en XPath)
Si on pouvait utiliser avec Schematron les extensions XSLT 1.1 pour les
appels à Java, on pourrait lever ces restrictions, mais je n'ai
pas trouvé comment faire.
Je n'ai pas encore étudié Relax NG, mais comme XML
Schema, et peut-être mieux encore, c'est un language structurel,
i.e. on spécifie l'imbrication des éléments entre
eux. Schematron apparait comme un langage de spécification de
contraintes supplémentaires, à utiliser en
supplément de Relax NG, ou XML Schema.
Metadonnée UML
et Java
Maintenant pour les langages de conception, je pense qu'on a (presque)
l'équivalence:
XMI (UML), diagrammes de classe seulement ~ Java Beans
Le "presque" se rapporte aux associations n-n, qui ne peuvent pas
s'exprimer comme des propriétés sans une convention de
correspondance. On pourra typiquement pour une association n-n entre
classes A et B ajouter une propriété multi-valuée
dont les valeurs seront des couples A,B .
Evidemment en dehors des diagrammes de classes, UML offre plein
d'autres richesses, qui dépassent le domaine de la
metadonnée: diagrammes de séquence, d'état, cas
d'utilisation, déploiement, ...
La problématique est la même pour SQL:
SQL Data Definition Language ~ Java Beans
Les trois précités sont donc équivalents, ce qui
correspond aussi aux diagrammes entités-relations qui existent
depuis
longtemps.
Ontologies
Enfin il faut regarder du côté des "ontologies" et autres
réseaux sémantiques; on a:
RDF Schema < DAM+OIL
car DAM+OIL est basé sur RDF Schema. Mais dans ce
monde-là le paradigme n'est pas celui d'un document avec des
parties, sous-parties, données textuelles, et liens entre
parties. Ce paradigme est commun à SQL, Java Beans et XML. Ici
tout est basé sur la notion de "resource", qui dans un contexte
Web est typiquement l'URL d'une page Web. Mais en fait une resource
ça n'est rien d'autre qu'un identifiant
unique dans un monde clos dans lequel on fait des raisonnements. Une
resource
peut donc être vue comme un objet, une ligne dans un SGBD, un
concept,
etc. Une base RDF contient les fameux triplets (resource,
propriété, valeur). Mais ici on est dans un monde de
connaissance, pas dans un monde SGDB où une commande DOIT avoir
un client, un montant, une date, etc. Dans un réseau
sémantique une propriété peut
ne pas être remplie. Par example un "prospect" peut ne pas avoir
de
propriété "fonction dans l'entreprise".
RDF Schema permet de spécifier une hiérarchie de classes
et leurs propriétés. Mais au lieu de déclarer en
une seule fois (comme en Java etc) qu'une classe possède une
liste (fermée) de propriétés, on déclare
indépendemment des propriétés avec un domaine
d'application et une plage de valeurs.
DAM+OIL est très riche et à vue de nez, il y a à
peu près de quoi exprimer XML Schema :
DAM+OIL ~ XML Schema
et plus encore, voir "feature comparison
of XML, RDF(S), and DAML+OIL" . Dans DAML New User Roadmap on
trouvera des lectures conseillées pour chaque type de lecteur.
Dans XML Schema l'accent est mis sur l'aspect structurel du document
XML, dans un but de
validation. Par contre dans DAM+OIL l'accent est sur une
modélisation
de la connaissance, qui peut se traduire en structures isomorphes
à
celles de XML Schema, mais qui permet en plus des inférences
logiques.
Quand à Topic Maps, la dernière fois que j'ai
essayé de lire la spec., j'ai renoncé par son
absonceté! Je suis habitué à la prose W3C, mais
là c'est un autre niveau de jargon !
Il y a cependant des didacticiels: Topic Maps
(Introduction). Les concepts de base de Topic Maps sont: topic,
association, scope. Par rapport à RDF et DAM+OIL, topic
correspond à resource, association
à propriété. "scope" n'a pas d'équivalent
direct
et permet de définir un sous-contexte. Apparemment Topic Maps
n'a pas
la richesse de structuration logique de DAM+OIL, c'est un vocabulaire
métier
pour la gestion documentaire .
Les ponts entre
formats de metadonnée
Castor est un outil de choix
pour échanger, à l'exécution, entre:
- SQL Data Definition Language
- XML Schema
- Java Beans
On peut l'utiliser pour des projets centrés XML, ou
centrés Java. On peut générer des classes à
partir de XML Schema,
mais pas l'inverse. Donc dans le cas d'un projet centré Java, on
ne
pourra pas valider le format d'échange XML.
A partir de XMI
ArgoUML ( http://argouml.tigris.org/ ) est
un éditeur UML libre. Il permet d'importer des classes Java et
de sortir du format XMI. Ensuite ce format XMI pourra être
transformé
via XSLT en :
- XML Schema
- SQL Data Definition Language :
- UML2SQL ;
je ne l'ai
pas
testé; ce serait prometteur si le projet avait bougé
depuis 2000; il génère aussi la
transformation
de la base quand la metadonnée a changé.
- implémentations BMP (Bean Managed Persistance) pour un
serveur
EJB : : il fait ce qui est probablement le plus difficile,
c'est
à dire de lire le XMI . En reprenant certaines des
transformations
XSLT de Butterfly, il doit être possible de générer
aussi
du XML Schema.En fait Butterfly a une architecture extensible pour
générer
en parallèle plusieurs formats: source Java EJB, SQL, etc.
- Representing
UML in RDF
A partir de SQL
Il y a un outil intéressant sur le site iBATIS, sql2ibatis
, qui génére le code Java et tout le reste à
partir de déclarations SQL (create table).
Conceptions,
métadonnées et ontologies
réutilisables
Il y a des choses disponibles, mais on est encore loin de ma vision de 2002 : OO + free software =
synergy
[dream]. En fait, je comprends la raison maintenant que je travaille
à un modèle de données UML dans le domaine de la
téléphonie mobile. Le confidentiel est beaucoup trop
mêlé aux parties génériques, ce qui explique
que de tels modèles ne sont pas publiés.
???? à compléter
Contraintes
Les contraintes permettent d'ajouter une sémantique
extrêmement précise et formelle au classes par les
invariants, et aux méthodes par les pré- et
post-conditions.
Bien qu'il soit peu utilisé, le langage OCL est un choix naturel
pour écrire des contraintes en UML dès qu'elles
dépassent les contraintes de multiplicité qui sont
exprimables dans les diagrammes.
Voici un exemple d'invariant créé avec ArgoUML.
L'idée
derrière cet exemple est d'utiliser un modeleur UML comme
éditeur de correspondances
objet-relationnel. Ici A serait une classe et B une table.
context A inv mapping : x = b.y
Diagramme UML
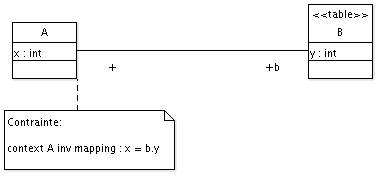
Le générateur de code d'ArgoUML génére un
commentaire JavaDoc exploitable par XDoclet:
public class A {
/** @invariant mapping: x = b . y */
public int x;
Voici une petite
présentation sur OCL, qui pointe quand même sur
certains manques et imprécisions dans la spécification.
Outils logiciels
En gros on peut faire pas mal de choses avec un XML Schema, mais
comment
créer / éditer un XML Schema sans passer par l'outil
propriétaire
XML Spy ?
Une idée est de passer par un des nombreux éditeurs UML,
puis de générer un XML
Schema à partir du XMI .
Pour cela, il n'y a pas pléthore d'outils. UMT est un outil
prometteur, encore un peu jeune, qui fait aussi de la
génération SQL et des traductions entre dialectes XMI. Il
y a un outil propriétaire
qui s'appuie sur le meta-modèle MOF pour XML Schema de l'OMG.
- Générateurs de code Java à partir de XMI
: butterflycode - AndroMDA.
- Protégé
- En peu d'années, Protégé est devenu le couteau
suissse de l'IA avec 20 ou 30 plugins, un peu comme eclipse dans son
domaine:
- traduction des formats IA: Clips (natif,) OWL, Prolog, ...
- import et export en XMI
- connection à une base relationnelle
- XML Ontology : à voir : génére
un XML Schema correspondant à l'ontologie
- DTD to XML
Schema
translator - CyberNeko
DTD Converter
: font la même chose
: convertir une DTD en XML Schema.
- les liaisons XML/Java : Castor, JaxMe,
XMLBeans, XStreams: chacun fait la correspondance à sa
façon, notamment sur l'adaptation des noms
d'éléments XML à Java
- oil2xsd
- Some XSLT stylesheets converting an OIL ontology to XML
Schema.
- SchemoX
génère des formulaires à partir de XML
schemas
- n'a pas bougé depuis 2000
References
http://www.w3.org/RDF/
http://www.w3.org/TR/rdf-schema/
Resource Description Framework (RDF)
http://www.xml.com/pub/a/2001/12/12/schemacompare.html
Comparing XML Schema Languages
by Eric van der Vlist
December 12, 2001
Métadonnées: une
initiation
Dublin Core, IPTC, EXIF, RDF, XMP, etc.
Sommaire